

Extracting text trapped within images in PDF files allows unlocking vital information for searching, editing, and data reuse. Manually retyping text from images is extremely tedious.
This article explains optical character recognition (OCR) technology that can automate text extraction from PDF document images. We cover the basics of how OCR works, step-by-step usage guide, and tips for optimizing text extraction through improving image quality. Follow these tutorials to effortlessly retrieve text from PDF scans and images.
Understanding Optical Character Recognition (OCR)
What is OCR?
Optical character recognition or OCR at its core refers to the automated conversion of typed, handwritten, or printed streams of text characters that are trapped within image scans and graphics into structured, machine-readable and fully editable digital text through leveraging advanced artificial intelligence algorithms.
How OCR Technology Works
Specialized OCR software processes images containing text by programmatically identifying patterns of characters via object detection, and then intelligently converts the pictures of sentences and passages into actual text strings. This extracted text content can then be effortlessly edited within word processors or exported in a structured format.
Benefits of Using OCR for Extracting Text from Images
Automating text extraction from PDF document images through AI-powered OCR solutions enables capabilities ranging from searching within previously text-less scanned files based on identified words to permitting complete editing of now liberated passages instead of static, non-selectable images. It eliminates the need for manually retyping potentially thousands of words trapped in graphics.
Free Online Tools for Extracting Text from Images in PDF Documents
Tool 1: PopAi
Features
PopAi provides a user-friendly cloud-based OCR API not requiring any complex installation or setup, which can reliably extract text even from grain scans and distorted images into editable formats. This AI pdf reader supports extracting text within PDF files as well as all common image formats. Furthermore, it has multilingual capabilities, being able to recognize text beyond just the English language.
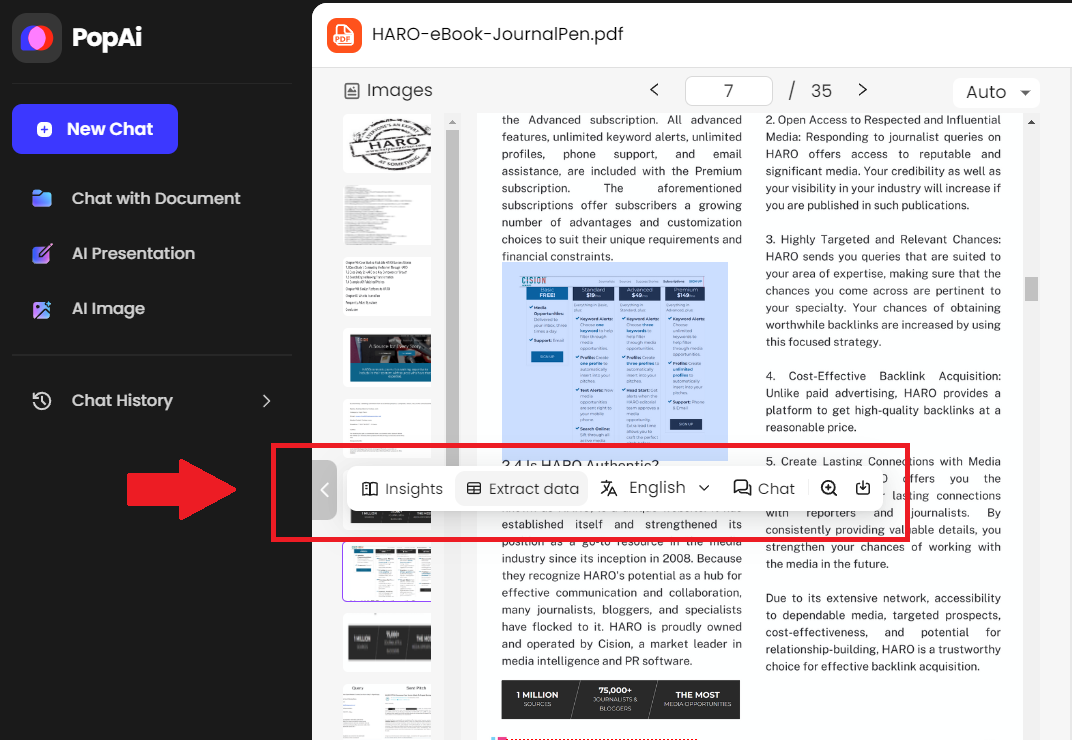
How to Use
This tool has an extremely simple workflow – users simply upload a target image, diagram or PDF file containing embedded text graphics through the intelligent web portal. After uploading, allow a few seconds for the AI model to rapidly process the documents. Finally, copy or download the machine-readable extracted text from images in the clean output.
Pros and Cons
A notable advantage is the easy-to-use interface and integration requiring no learning curve coupled with robust text extraction abilities even from poor quality scans. However, free accounts face file size and monthly processing limits which may necessitate paid plans for large volumes.
Tool 2: Adobe Acrobat Pro DC
Features
Adobe Acrobat Pro DC provides a full-featured PDF editing environment with seamless built-in OCR capabilities powered by an AI engine, touch-enabled interfaces optimized even for tablet devices, and leverages enhanced machine learning image processing algorithms for maximizing text recognition accuracy.
How to Use
The workflow involves simply opening up an image-based PDF file directly within the Acrobat desktop app, then selecting the dedicated OCR menu option labeled ‘Recognize Text’. Finally, save the extracted text if you need to export it outside of the document separately.
Pros and Cons
A major advantage is the tight integration of OCR functionality into Acrobat’s existing robust PDF editing toolkit with no learning curve. However, a paid perpetual license is required which increases costs for occasional users.
Step-by-Step Guide to Using OCR for Extracting Text from Images in PDFs
Selecting the Right Software or Online Tool
First, identify organizational needs regarding expected processed languages beyond English, desired degree of text extraction automation, existing document workflows, and budgets or cost considerations when shortlisting the best OCR solution. Typically, occasional small jobs suggest leveraging online OCR APIs, while batch processing high volumes of documents benefits from locally installed desktop software.
Uploading the PDF Document Containing Images
Once an appropriate OCR tool is selected, upload or import the target PDF file or specific images through inbuilt features onto the platform interface. For example, drag and drop files within Acrobat, or use web upload portals for a cloud API.
Running the OCR Process
Upon uploading, allow several seconds to minutes as needed for the artificial intelligence model driving text recognition to fully analyze all embedded images and graphics within the PDF document to extract out all identified streams of text by auto-initiating processing flows.
Checking and Editing the Extracted Text
Review the text recognition results panel or access the output file containing all identified text strings to manually correct occasional misinterpretations on ambiguous or obscure characters that may confuse AI if the document quality necessitates further intervention.
Saving the Text in a Usable Format
Finally export or save the OCR processed text stripped from images as a separate, cleanly formatted text file such as TXT, DOC or DOCX for easily accessing the now liberated passages outside of PDF format within common word processors if needed for further editing or distribution requirements.
Tips for Optimizing Text Extraction from Images in PDFs
Using High-Quality Images
When capturing images of text paragraphs during scanning flows meant for eventual usage in OCR pipelines, always use sharp, correctly focused images with sufficient lighting and maximize resolution to improve text character recognition accuracy.
Adjusting Image Resolution Before Extraction
For existing low resolution scans, increase pixel density through interpolation methods before OCR where permissible to moderately boost clarity and enhance extraction precision without introducing excessive distortion.
Ensuring Clear, Legible Text in Images
When creating text using graphics apps to embed within PDFs, use sufficiently large, legible font sizes that minimize character ambiguity. Also minimize background noise, complex textures, and clutter which could obstruct OCR algorithms from cleanly isolating characters.
Proofreading and Editing the Extracted Text for Accuracy
After text extraction completes, double check final output thoroughly through spell checks alongside manual reviews to fix occasional recognition errors prior to further usage, while retaining contextual integrity of content.
Conclusion
Liberating text trapped within PDF document images through OCR automation eliminates tedious retyping needs while enabling full content utilization. Follow these best practices using efficient tools like PopAi or Adobe Acrobat Pro for optimized text extraction from scans and images to aid analysis and searchability.





Be First to Comment